TTN Relays
In part prompted by Marcus Wolschon's blog post about leaving Thingiverse I have been thinking a bit more about Githubiverse and it's potential role in the Thing Tracker Client I am writing.
Githubiverse is a nice little hack to take advantage of Github Pages to serve a basic landing page for 3D printing projects. It has a nice advantage that it is all client based code and requires no web back-end (other than a Github repository of course), utilising the Github API to retrieve the data it needs. Unfortunately Github then decided (quite reasonably) to limit the number of anonymous requests that can be made by a client to 60 per hour, and considering each Githubiverse page refresh requires several API calls this is soon exhausted. Because all the code for Githubiverse is publicly viewable it cannot take advantage of any of the authorisation schemes available, such as OAuth.
I have used the page layout of Githubiverse as the basis for displaying things in the TTN client, and have for some time being considering how to add a relay (or mirror) function to the client which will allow a persons tracker to be available even if the client is off-line (which I presume may be the case for many people - even I shut off my PC for hours of the day!). The important requirement for me is that any relay function should be independent of any particular vendor or product, i.e. everyone should be free to choose where they host any TTN relay node.
My initial thoughts revolved around hosting solutions, perhaps something simple in PHP so it can be used in a wide variety of hosting providers, but even this adds a burden on the end user which would make the TTN client unattractive to some. I think my current plan should provide enough flexibility to satisfy the requirements I have.
The client will create a static snapshot of the tracker which is ready to upload or copy to a web server. This snapshot has two roles, it serves up the information required by other TTN clients, and also provides a basic website where people can browse the tracker and download the content. The relay site will be easy to modify for those wishing to change the look and feel of it, and a future feature may be to make it easily skinnable.
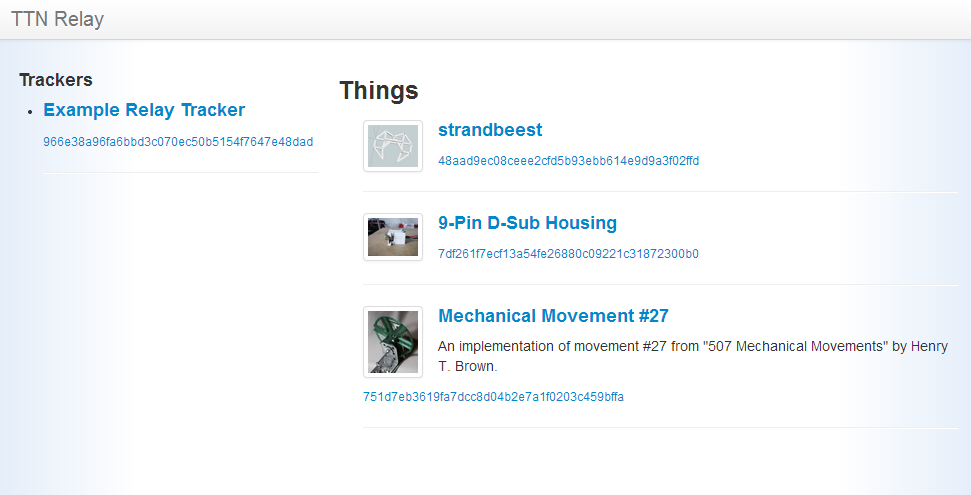
- Google Drive / Dropbox / etc.: By copying the relay to a local folder shared by Google Drive, Dropbox and similar services, it can then be accessed as a regular static website. (I don't know if this is still possible with recent Dropbox accounts, but with older ones such as mine which have a Public folder it is).
- Google Drive:
https://www.googledrive.com/host/0B1a6oY6Gw7BJUWZvY2xxbWxBbUU/#/ - DropBox:
https://dl.dropboxusercontent.com/u/22464622/TTN/relay/index.html#/
- Google Drive:
- Github / Git: Integration with Github should be relatively straight-forward, pushing a local copy of the relay to a github-pages branch should provide a similar experience to the current Githubiverse solution. Interfacing with git should work over something like gift or maybe even git.js. And of course it doesn't have to be restricted to Github, other git repositories could also be used, opening up a host of other options.
- FTP / Rsync: A third candidate is to upload the relay to a hosting site, and a plethora of synchronisation options are available.
- Hosted:
http://garyhodgson.com/ttn/relay/#/
- Hosted:
The client should ensure that all internal references are valid for the machine readable aspect of the relay (via valid relative refUrl attributes I think). It could also provide integration to the wider Tracker Network potentially providing search capabilities.
This is all in addition to having the option to host the information directly from the TTN Node itself should one wish to. The relay concept simply opens up more opportunities for sharing the data - which is the core aim of this project.
Thoughts and opinions are always welcome, either in the comments or on Google+