Thing Tracker Network Client : Status Report
A little while ago I started work on a Thing Tracker Network (TTN) Client, with the intention of having at least a working beta before the end of the year. This proved to be rather optimistic, and whilst the work is still ongoing, I thought it useful to write a post outlining the goals I have in mind, and the challenges I believe have to be overcome. At this stage I believe the core design is reasonable, and so feel comfortable asking for opinions, feedback and help.
The client concept differs from many alternatives by it being a distributed system. Whereas the majority (all?) of the existing 3D printing repositories require registration to a central service, this client, in conjunction with the TTN, requires none, and the various Things are stored in the network itself. This brings several interesting challenges as I shall list later.
A few of the factor driving the design decisions are:
- The client should be cross-platform, and easy to install and use for a wide range of people. (Whilst recognising that the majority of makers are technically very competent.)
- Should not rely on central services.
- Should offer some degree of security, i.e. the ability to verify and trust nodes and their content within the network.
After several discussions with others about the design, the (current) outline of the client is as follows.
- A standalone application, built on Node-Webkit, which uses a Distributed Hash Table (based on KadoH) to connect to other nodes in the Thing Tracker Network.
- Information is passed between nodes via RESTful Web Services (using Restify), this includes sharing information about Things and lists of Things (i.e. Trackers) - following the TTN Specification.
- Sharing of actual content, i.e. the actual design files, is planned to run over BitTorrent, however, lacking suitable BT client libraries, in the short term it will be implemented as direct transfer over HTTPS.
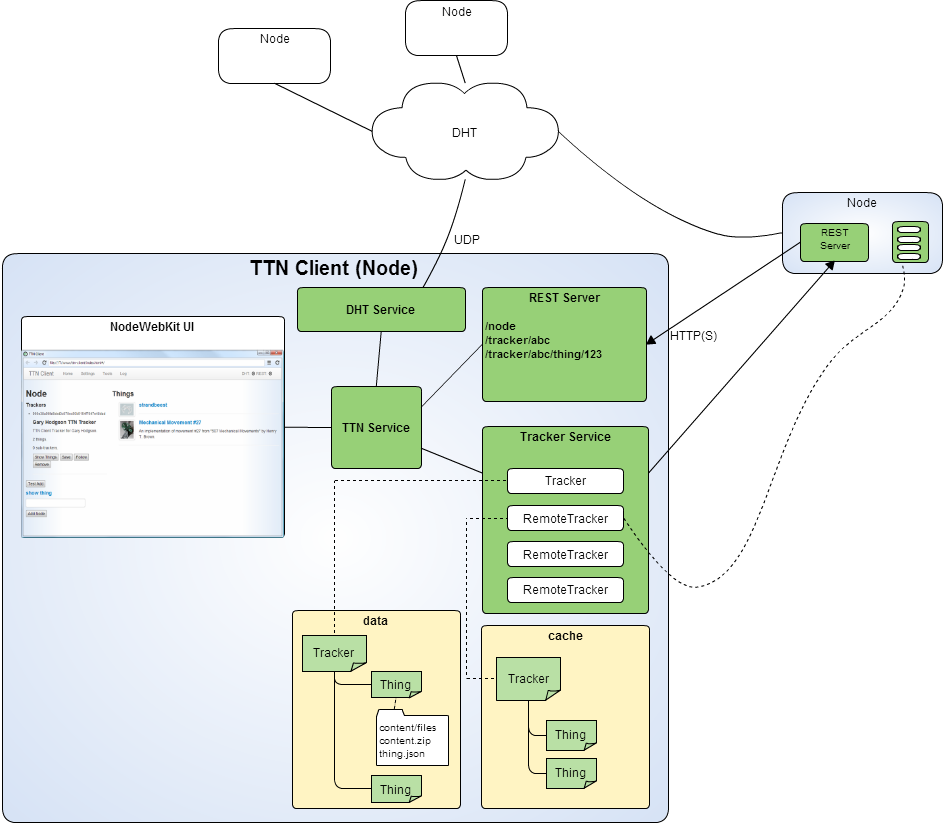
TTN Client Architecture
Even this simple sounding app brings with it challenges.
Redundancy
How to ensure that a node's content is still available even if the originating node is offline?
It has to be assumed that only a small portion of nodes will be online 100% of the time. This is where using BitTorrent for the content distribution might have a real benefit, besides resource sharing etc, as the content would be available on another network.
The current design allows for content files to be stored anywhere, and so they could be made available in the cloud (Dropbox, personal web server, etc), but it would make for a better user experience when such remote storage was seamlessly integrated into the client in some way.
My current thinking is that each person can opt to have their node act as a relay for other peoples trackers. That is, I might decide to store and make available the tracker and content for, say RichRaps, designs, and should he be offline when someone wishes to download one then the client could ask the network for alternative locations. This fits with my vision of an ecosystem building up around the TTN - where a variety of clients interact in different ways: relays, aggregators, filters, and so on. Someone may decide to donate resources to relay particular designs on behalf of the community, for example the RepRap project could run a client which acts as a relay for all RepRap designs. This would differ from existing offerings in that the original data remains linked to it's originating node for purposes of ownership and attribution, plus the data would be replicable by other nodes - i.e. the content is not exclusive to one particular server, rather it just happens to be regularly available at that node.
This is one of the major benefits of this design if we can pull it off: We shouldn't be dependent on the services of others. If a repository falls offline sometime in the future there should be enough redundancy in the network to ensure that designs remain available.
Security
How to verify that a Thing originates from a given node?
The current design uses Public Keys and Signatures to build a web of trust within the network, to verify that a piece of information originates from the node it claims. This is an area that will need a lot of work in order to make the system trustworthy.
How to store Things retrieved from possibly untrusted sources?
The app runs inside your network and has access to your local file systems, therefore it is very important that any interaction with external resources be controlled and secured as much as possible. For example, I expected my locally running Avast anti-virus to recognise when the client downloads an infected file, but preliminary tests seem to indicate this is not the case, at least with the original settings which do not scan every file by default. One might be able to use a portable virus scanner, such as ClamAV, but this may conflict with making the client easy to install, and is another component to have to manage.
Communication
How to announce new Things, or updates to existing Things, to the network?
This is an area I have yet to implement, but I suspect may turn out to be one of the more interesting parts of the client. Using a DHT to connect nodes may allow for interesting ways of passing information between the nodes. For announcing, some form of message passing approach may be best, or some form of publish-subscribe model. These updates could potentially be stored in the DHT itself.
How to discover new nodes?
The primary way of including new nodes would be by manually adding the node ID which is gained "out of band", via forums, blogs, etc. The client would then look up the information for the node, and optionally traverse the trackers (and nodes) that that node itself is following. I can quite imagine that if I were to start following RichRaps node then I may be interested to follow those that he is following too. In this way the network effect should yield a large set of possible trackers to follow.
An alternative way might be to have a "listening" mode for the client, which listens on the DHT for new nodes and adds them to a list to be reviewed whenever you wish. Furthermore there could be a "promiscuous" mode which listens for new activity and automatically adds the trackers and things it picks up to the local tracker. This is how I imagine an indexing or search-engine client might operate - trawling the network for new information. Again, by promoting the TTN specification, rather than any particular solution, the possibilities as to the type and function of the participants of the network are boundless.
Storage
How best to store Thing and Tracker data locally?
If a thing is updated regularly then how to efficiently record these changes without having many redundant copies cluttering the local harddrive? The immediate idea might be to use something like git to store local Things, but that again may conflict with the ease-of-use/installation driving factor.
Versioning
How to handle the fact that Things may have multiple versions?
This adds another complication to the network, not only in terms of organisation and storage, as mentioned above, bit also in terms of hereditary and attribution. How can we effectively track the ancestors which make up a design?
Usability
How should the application look and feel? Could it be skinnable, open to extension, etc.?
By basing the design around the TTN, rather than a particular client, the hope is that others can take the client as a basis for their own designs, or build something from scratch. By making the information available over RESTful web services the barrier to creating a client is greatly reduced.
Interestingly the UI aspect of the client appears to take a large proportion of the time, not due to technical reasons, but because of trying to decide how to make the client accessible to non-technical people.
The application uses AngularJS for the front-end, and this certainly helps reduce the amount of boilerplate in getting the app up and running.
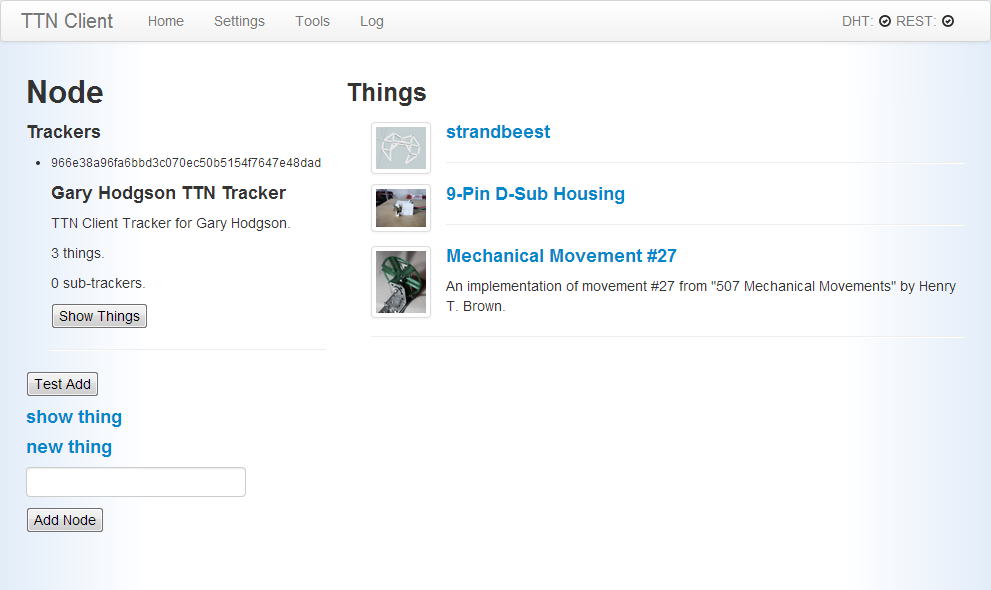
Work In Progress - Tracker Page
Use Case
The above gives a slight indication as to the aspects that I have been considering, and this is by no means an exhaustive list. I'd like now to run through a use case to show how I imagine the client to work in practice. It is quite broad, but also dives deep into the technical details now and again to exemplify aspects of it.
Setup
- First of all someone downloads the latest version of the client and runs it on their local PC.
- Because it is the first time it has run the client recognises that there is no local keys for the node and so generates both public and private keys, and uses the hash of the public key as the node id. These values will remain for the life of the node (although we need a way of handling the case when a node is compromised and the keys have to be regenerated - you no doubt see how these seemingly small features give way to ever more issues to deal with!)
- The user is prompted to optionally provide information about the node, and set particular parameters, such as where to store files locally, whether to automatically cache trackers, etc.
- The client comes with several well-known bootstrap nodes configured, and these are contacted to announce that the new node is joining the network.
Browsing
- The client may optionally come with a set of nodes pre-installed, which are contacted and their trackers retrieved and displayed.
- The user may choose to browse these trackers and their Things.
- Should they choose to download the content locally, the target node is queried for the content and if available a zip file of the content is stored locally.
- Optionally, if the node is verified (more later) then the zip file might automatically be unzipped in the client cache so that individual files can be accessed from within the client. Otherwise the user would have to confirm any action involving the remote content until it is deemed verified, e.g. after it has been scanned for viruses.
- Here we see an opportunity to use the network to help verify the contents of a particular Thing. Some form of flagging scheme may be useful, whereby nodes can flag content as being malicious or objectionable, and if nodes I trust and have verified, my friends to speak, have marked a Thing as being suspicious I might take extra care when working with it, or ignore the Thing, Tracker, or even node, entirely.
- The user may choose to manually add a node to his list to follow. The node id may have been retrieved via a blog post, email or other means, and is pasted into the client. The remote node has a status of "unverified" at this stage.
- The remote node is contacted and a list of trackers is returned, these are displayed in the client.
- If the node is not available then the client may ask the network if anyone else has a cached copy of the node's trackers.
- The remote node also returns information about itself, including its public key.
- The user may then optionally choose to verify the node by providing the fingerprint of the public key belonging to the remote node. This would be at best obtained out-of-band, via a different medium to the source of the node id, and in a way in which the user can be sure originates from the node owner. Note that at this stage no claims are made as to the security of this method. This is one area which would require input and review from those with much more experience in application security. Personal contact, email, and multiple verified sources, may all help in instilling a level of trust that the fingerprint of the node key really originates from the node owner, and that to a certain degree the node can be verified. Furthermore, the option exists to build a web of trust, whereby a node verified by node I have verified has more weight than an unverified node. This is something to be explored further.
Publishing
The user then may choose to publish their own Thing in the network.
- As this is a fresh install no Tracker yet exists, therefore the user would be prompted to create one. The thinking being that people would be free to create several Trackers, each of which may track different types of projects. For example one tracker for personal projects, one for RepRap related designs, another for the local hackerspace, etc.
- To create a Thing, a form would prompt for information about the Thing, including the location of the files that make up the release.
- The Thing could be saved in draft form so it can be worked on over a period of time.
- When the release is ready to publish the client will zip the content into a file ready for others to download, add the Thing to the Tracker, and send an announcement to the network.
- If the user then finds a typo, or other minor fault, in the release, they may choose to edit certain fields whilst the version remains unchanged. I think that for certain changes it would be wise to ensure that the version is incremented.
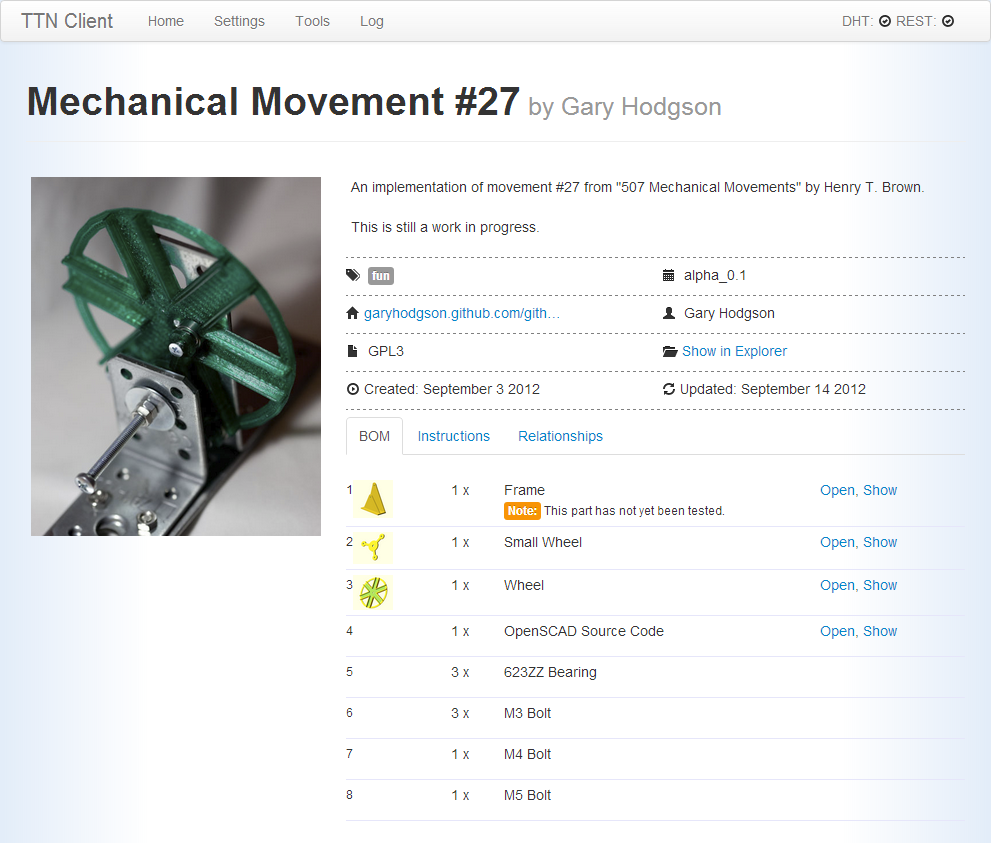
Work In Progress - Thing Page
Hopefully this gives an indication of the factors involved in designing and producing such a client. There's a whole lot more in addition to the above. the challenge now is simply finding the time, and motivation, to produce a client that can at least give a reasonable experience for those willing to try it out. I'm a firm believer that if the Thing Tracker Network Client can be made to work then it could make a huge impact in the maker world, bringing control back to the individual.
I should say that the code so far is available on Github, but I really can't recommend trying to use it (although I'll help anyone who wants to have a go) as the design is still in a state of flux, plus the code quality leaves a lot to be desired as several different approaches and techniques have been tried, and it really needs a good refactoring to make it a bit easier to delve into. However, with that warning, the project can be found here: https://github.com/garyhodgson/thing-tracker-network-client
Comments
-
Tony
23-12-2013 11:29
Hey Gary
Great work! This feels a little bit like some work I did years ago on a prototype for a distributed enterprise backup system that used spare storage space on all the networked PCs within an organisation to backup that data. It was a sort of self hosted enterprise cloud storage before the concept of the cloud existed in its current form. In the end the encryption overheads required made it untenable and it never got off the drawing board.
I think its important for you to assume two things. Firstly people in general are concerned primarily about the files that they want, not where they get it, in other words a search function should be at the core of the system's design rather than a web of trusted nodes with the associated maintenance. Secondly that every object/zip/transfer should be untrusted and assumed to be infected so some security and flagging system as you mention would be needed. Given these two points, is there much advantage to having a trusted node? I would be likely to discover the things I want (say "christmas tree star") by searching the network and downloading the one I liked the look of. I would then assume what i had downloaded required virus scanning before opening.
Having the data on as many nodes as possible is a good thing - speeds up the network and improves resilience - it should be the default that when a shared file is downloaded, the downloading node then seeds the file from then on. Given that most "thing" source files are quite small, node storage of 1gb or so would allow for a lot of things to be mirrored around the network. Once a node's assigned storage was full then the oldest files can start to drop out the bottom of the storage (with the ability for the user to flex the size and flag certain files as always keep). Popular things would be widely distributed, less popular things no so much and if you have something that you want to remain available, but nobody else wants, then you need to keep your node online to keep in on the TTN.
I think, at least initially, that version control can be left to the "thing" producers. So if I have a later version I increment the version number and the search function lists both versions, users are then free to choose the one they want. I may or may not choose to stop seeding the older version at which point, if popular it will remain on the network, if unpopular will die out. Minor typos etc would actually be more difficult to handle though because it would require some form of push function to send the update out to every node that had the "thing" to make the changes - that would leave it very open to abuse. (The ability to push an update could allow deletion of content on the network or mass infection of content on the network)
Attribution can be left to the users as well - add a link(http,magnet,something else) to the new object to reference those its based on.
I think to make this really popular and powerful then having web based search engines/trackers that non users can search for objects would be great (think isohunt etc), if the user then wants to download the thing they then use a TTN client and, hopefully, continue to use that client and thus become a node on the network.
Something like http://btappjs.com/ might be useful for bt integration.
Cheers
Tony
-
Gary Hodgson
23-12-2013 12:21
Hi Tony, Thanks for the detailed comment! All good points, particularly regarding the need for search, and how the typical user will want to interact with the system.
I am also coming to the conclusion that it will have to be the end-users responsibility to ensure any content downloaded is scanned for viruses etc. I think if the client makes it abundantly clear it should reduce the number of problems encountered.
I can certainly imagine a specialised client which provides a rich search capability in a nice web interface, which uses the network as a backend, and caches the metadata and content to make it directly downloadable.
Having the client act automatically as a store and relay for downloaded content is the way I want to go, but also giving the user the option to pick and choose what content to relay, for example if their bandwidth or storage options are limited. I expect that (if this works of course) that there will be enough nodes permanently online willing to relay a lot of the content that makes up the network.
One question: in the backup system you designed, you say the encryption made it unworkable - is this because all content was to be encrypted at runtime? Or because of the amount of data involved? The current plan is to only create signatures for the content at creation time, and so I hope to offset any intensive crypto stuff, so I think this shouldn't be a problem as it stands.
Thanks again for the feedback - keep it coming if you have any more! :)
Cheers,
Gary
-
Tony
23-12-2013 13:32
Hey Gary
I agree, having content digitally signed will have no real impact on the network performance. The issues we had do not apply to the TTN so don't worry about it, for information though:
I worked on the the backup system prototype as a (junior) network engineer rather than part of the core programming team, also it was 14 years ago so memory is a little hazy. The reason why the encryption was such a headache was because the individual PCs were considered untrusted storage - so everything stored on them needed to be inaccessible to the users of those PCs, and not interfere with their primary function as office workstations. Also we did not want to have to relay everything through a central server for encryption/decryption, we wanted to implement a load balancing/location system across multiple sites. All this made it not worth the time in the end. (Killed by cost benefit analysis - we ended up buying more servers and bandwidth!)
Cheers
Tony