Thing Tracker Network Update
Time flies! It's been almost two months since I posted about the Thing Tracker Network (TTN). Recently progress has slowed down to a crawl, mainly due to other priorities (RepRap Magazine, work, family, imminent house move, etc, y'know the usual things), and also because I am taking a slight detour with regard to TTN which I want to briefly describe here.
After the initial excitement of announcing the proposal there have been a series of suggestions and improvements which I have attempted to merge into the specification. I think the current version is a reasonable basis for defining Things and the relationships between them. Expanding to include the possibility of adding detailed bill-of-materials and tracker metadata, for example.
A quick aside: there are now several resources that make up the infrastructure of TTN which I will quickly list:
- The website is the public face of the proposal and will be updated on an ad-hoc basis to reflect the current state of the proposal.
- The Github repository holds the live specification along with examples. In the near future it will hopefully hold reference libraries, tools, and example applications. There is also a wiki and issue tracker to handle documentation and tasks.
A Google+ communityto hold discussions, and an associatedG+ pagewhich is the source of "official" statements (as opposed to my personal thoughts as a fellow hacker).
Several people have mentioned in passing that the technology of the fabled Semantic Web, now known as Linked Data apparently, may be of interest. A little internet research led me to a useful resource in the Linked Data Book, and the more I read of it the more I realised that the TTN sounds like it is basically trying to be a Linked Data vocabulary. Consequently I think it is worth exploring the idea further, to see whether the goal of the TTN should be to define such a vocabulary along with tools and libraries to support it.
There are several considerations should a Linked Data approach be taken.
- Many of the concerns that have cropped up in discussing TTN have already been discussed in the Semantic Web world, such as identity, security, and reliability.
- A set of tools and libraries have already been developed which could potentially be utilised.
- Linked Data seems ideally suited for describing the types of things the TTN is all about.
- Using the language and specifications of the Semantic Web might interface the TTN to the wider internet of things, as espoused by Tim Berners-Lee.
- The Linked Data specifications (e.g. RDFa,RDFS,OWL) are, however, more complex than those originally envisaged by TTN, and the learning curve to fully understand how the network works may be steeper.
- Using a recognised and widely adopted standard would seem preferable than devising a proprietary, albeit open, standard.
From my reading so far, I believe the following would be possible using Linked Data:
- Define a vocabulary using RDFS (Resource Description Framework Schema) which would be similar (if not identical) to the current TTN json schema.
- Mark up a Thing with metadata attributes using one of the following ways:
- RDFa (Resource Description Framework in attributes) to embed the TTN attributes within a web page describing a Thing.
- JSON-LD (JavaScript Object Notation for Linked Data) to describe the Thing in a JSON document.
- Traditional RDF (Resource Description Framework) in an XML document.
- Use existing libraries, or build new ones, to interact and work with this data.
In fact I hope that the RDFS & JSON-LD combination might already be very close to the work we have done so far.
To date my playing and experimenting has been limited. I have started formulating an RDF Schema (thingtracker.rdfs) and have added some RDFa to the example Githubiverse site (http://garyhodgson.github.com/githubiverse-tst), which appears to be readable according to the few tools I have tried out.
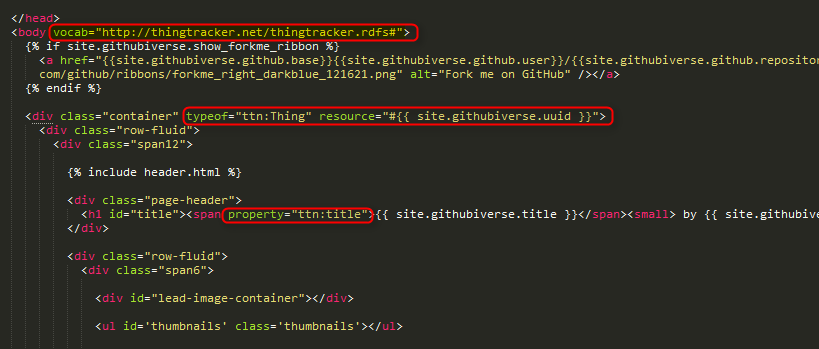
Snippet from source html. New RDFa attributes highlighted.
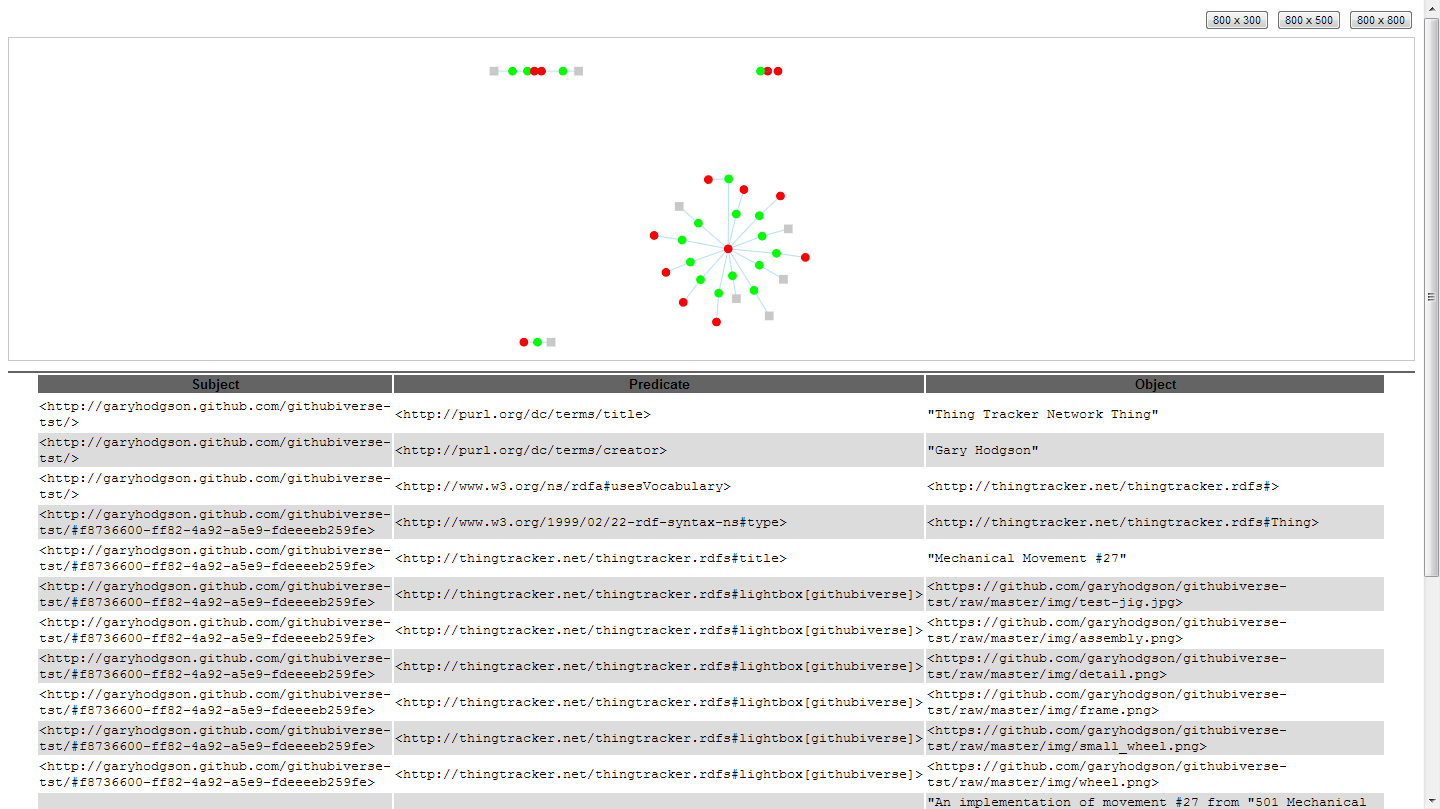
RDFa parsed using Green Turtle RDFa extension for Chrome browser.
There is a whole raft of things I still need to learn (help & guidance very welcome!), and this is still only an exploratory dive into Linked Data, but so far I feel it is worth pursuing further.
Comments
-
dzach
10-03-2013 18:59
One other ad hoc technology that is easily applicable to web pages and has seen success in the Semantic Web world is Microformats. Many popular web platforms, including Wordpress, that this site uses, Google etc, make extensive use of the Microformat specification, see for e.g. hAtom.
Firefox had a plugin for taking advantage of mf on web pages, named 'Operator+', I'm sure the new elements that appeared in HTML5 will give structured content a good boost, given time.
-
Gary Hodgson
10-03-2013 20:50
Hey dzach, I had considered microformats but came to the conclusion that RDFa is more extensible and would offer more possibilities in the future. Perhaps I should reread the microformats doc a bit more, but I got the impression that it's popularity stems from addressing a particular set of needs (hCalendar, hCard, hProduct) but wouldn't satisfy the needs of TTN. As mentioned in the post, I am still just learning all this, so I will happily be corrected.
-
dzach
10-03-2013 23:29
Gary
Indeed, RDFa is more extensible, but requires effort and one has to go out of the usual way of authoring a web page. My own brief exposure to RDFa a number of years ago didn't lead to a practical result. On the other hand microformats (which I then arbitrarily extended to suit my needs) needed very little work from design to publish and felt more 'natural'. If gaining momentum is a prerequisite for success then ease of use is important too.
The microformat idea lies in using existing HTML attributes and elements in a web page. For instance, looking in a Thingiverse's page source I see:
...
(I hope the code comes out right)
That snippet of code contains the basic elements for a microformat design, in fact it could already be used as one, if only it were consistent and complete: the parent class is 'thing', class attribute 'img-polaroid' contains the front page image, the element with class 'thing-name' contains the thing's name etc.
The above is readily harvest-able automatically. The harvesting app can be a javascript bookmarklet running in the browser. Consensus in the 3D printing/maker communities could lead to a consolidated scheme for publishing object designs that everybody could use, as you describe in your Thing Tracker Network post.
For another example, had your 3dprint.development-tracker.info site followed this idea, it would be very easy for someone else to harvest that info and go or just do an educated search or whatever.
Now why would the 'establishment' want to conform to the standard giving easy access to 'their' data to everyone is a question that has no easy answer.
Just my 2 cents.
-
Gary Hodgson
11-03-2013 00:43
I agree that ease of use is an important factor.
One thing that bugs me about microformats is the double use of the class attributes (perhaps this isn't mandatory - I'll read up a bit more when I get chance). The class attribute already has a role and hijacking it to embed semantic data seems wrong to me (is there a way to prevent class name clashes with css?), whereas the RDFa (and microdata for that matter) use additional attributes which seems more resilient.
Adding semantic data to the development tracker is definitely a task on my todo list.
And promoting the benefits of an open, shared data model would certainly be a hard sell to those players who view the data as 'theirs', as you put it, and whose central aim is to make money. Taken from the viewpoint of someone wanting to share their data however and it becomes so obvious that the question disappears. That is, is the value in the data, or in the sharing of that data?
-
dzach
11-03-2013 02:45
Actually, it is this double use of class attributes that makes microformats interesting and easy to use. One can put many classes in a class attribute, if necessary, and satisfy both CSS and semantic needs. The 'class' attribute is very tolerant in this respect. But even better, one can give classes meaningful names that can be properties in an ontology scheme at the same time they areCSS defining attributes, without a problem. This exactly is what makes microformats easy to use within the workflow of a web page making process.
RDFa on the other hand, tries to formalize the property's vocabulary and in doing so it remotes itself from that workflow, becoming something that requires special effort to achieve and not simply adoption of a convention. There are advantages to that solution, but the special effort required is costly, and has no other use than define semantic metadata. In engineering terms I would say that the efficiency of the RDFa design is less than that of MF :)
In your Development Tracker category listing page for instance, you use class 'oddrow' to give different background to odd numbered rows, which at the same time are containers or 'entries' in the tracker system. To accomplish the same in a microformat manner you could enter in the class attribute 'class="oddrow entry"' and just 'class="entry"' in the even rows. Similarly, you could give proper class names to 'Title', 'Description', 'Source' and 'Status' elements, following a published microformat convention for a 'Thing' ontology and that's all you'd need to do. Or use the new etc elements of HTML5 with class appropriate attributes, thus doubling the ways to manipulate CSS and semantics for the content.
But I feel I'm imposing my preference here.
Cheers!
-
Gary Hodgson
11-03-2013 20:43
I'm enjoying hearing more about microformats, so feel free to push your preference here :)
I can see the "neatness" of utilising the class attribute, but what happens if we define a microformat with certain attributes, and one of these clashes with someone's existing css names? e.g. we set an attribute to be "title" and someone wants to mark up their page but already uses class="title" for something unrelated (but still valid, such as title of a person rather than title of a Thing) Is there a convention to circumvent this, or does the person simply have to alter their css naming to comply?
-
dzach
11-03-2013 23:54
For the MF to be valid a minimum structure will have to be in place, e.g. a 'title' class inside a 'thingy' class will separate the 'thingy' MF title from the rest. Another way of doing this ambiguously would be to use a special namespace, but microformats avoid using namespaces, as far as I remember. RDFa uses namespaces; a title property could be 'dc:title' for instance in RDFa.
To write a microformat spec there is a formal process that needs to be followed, which takes effort and time, but maybe it's worth it. I remember contributing a draft idea about a 4D time-space microformat 5-6 years ago, but didn't pursue it further. I don't think there is any proposal for an 'hThing' MF yet. Of course one can start using the microformat principles right away, without any formal proccess in place. I usually do that in any web page I develop, it helps me structure the content. Most microformats require 'examples in the wild' , that is, applications of the proposed MF in the real world, in a website.
-
dzach
12-03-2013 18:54
Reading again the description of Thing Tracker Network I was wondering if the established syndication formats could be of use.
Another way of announcing and sharing information and resources about one's creations would be the well known Atom and RSS syndications formats. If you look for example into Thingiverse's RSS feed source, you will find most of the "Thing Tracker Network" required data already present there. Subscribing to such a channel (or tracker) is done by just clicking the RSS button on the browser.
Speaking about namespaces in my comment above, namespaces in RSS can be used to extend it to any king of vocabulary that follows the W3C specification. I think, parts of the 'ttn' vocabulary that are not covered by the RSS spec can be inserted there with the help of an appropriate namespace.
Some sites offer the whole of their contents through RSS feeds. Github don't seem to be offering downloadable content information in their RSS though.
-
Gary Hodgson
12-03-2013 19:57
Hi dzach, I'm a big fan of syndicated feeds and agree that using them as a way of emitting Thing updates is a good idea. Being able to mark up the feed with MF, or RDFa, would mean downstream systems could use the data contained directly - which is really nice. It's on the list! :)